Daily Trend [12-04]
【1】Think before you speak: Training Language Models With Pause Tokens
【URL】http://arxiv.org/abs/2310.02226
【Time】2023-10-03
一、研究领域
NLP,延迟推理
二、研究动机
现有的 LM 框架中,生成第 K+1 个 token 总是操作看到的前 K 个 token(而不会更多),相反,作者希望花费超过 K 次操作来生成下一个 token,因此,作者提出通过向输入附加 M 个虚拟 token 来综合增加输入序列长度,从而将模型的下一个响应延迟 M 个输入 token。
In the current paradigm of language models, we compute exactly K embeddings v1, . . . vK in each layer, before generating the (K + 1)th token, pK+1. Our premise is that this limit of K operations is an arbitrary one. Instead, we wish to expend more than K operations towards producing the next token, pK+1. While something to this effect could be achieved by increasing the number of attention heads in each layer, we are interested in an orthogonal approach that introduces hardly any parameters into the network. The idea is to synthetically increase the input sequence length by appending M dummy tokens to the input, thus delaying the model’s next response by M tokens of input. In effect, this M -token-delay lets the model manipulate an additional set of M intermediate vectors vK+1, . . . , vK+M before committing to its next (output) token, pK+1. Intuitively, these vectors could provide a richer representation of the input (e.g., by attending differently), thus resulting in a better next token from the model.
三、方法与技术
(1)在Pretraing过程中,选用”
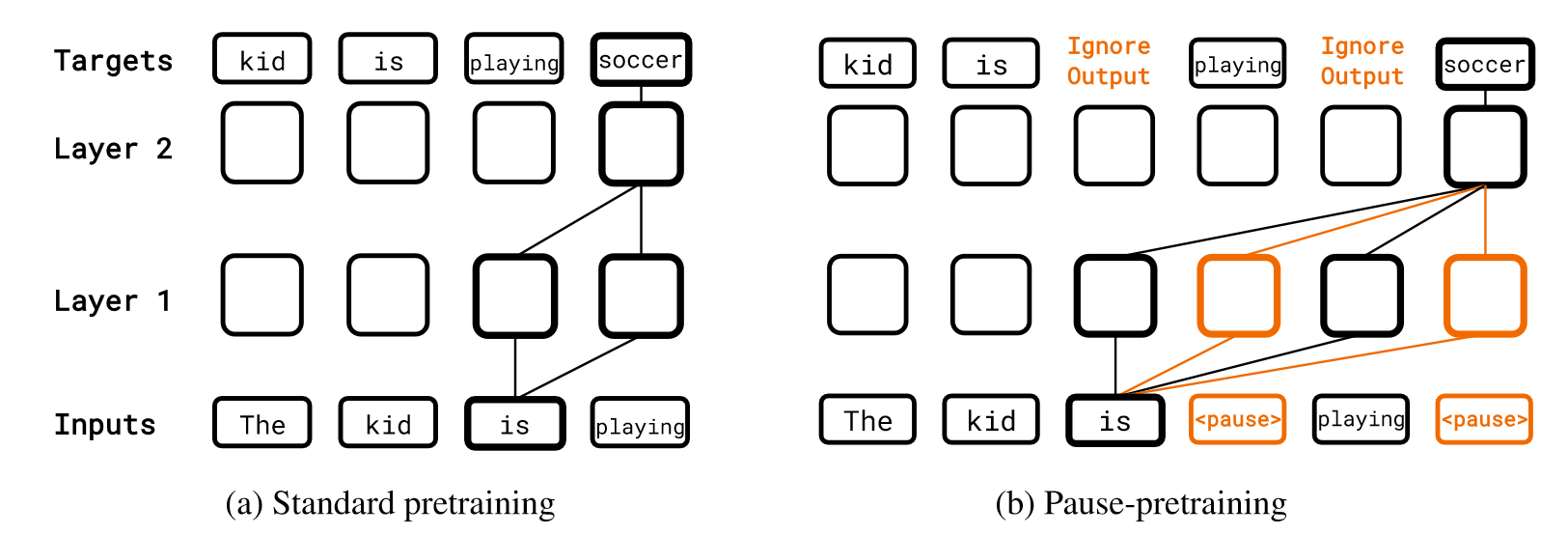
Figure 2: Standard vs. pause-pretraining.
(2)在Finetuning过程中,将”
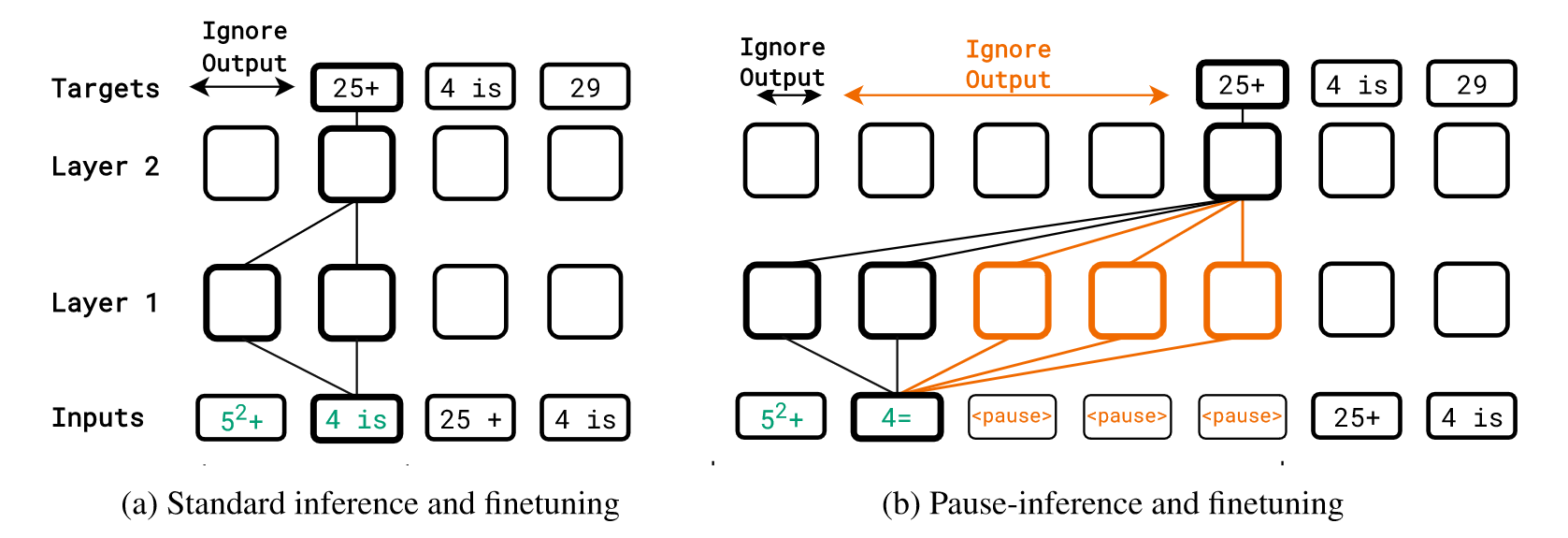
Figure 1: Standard vs. pause-inference (and finetuning).
(3)在Inference过程中,同样将”

(4)作者排列组合 标准/“暂停”(方式) 预训练/微调(阶段) 做了很多实验,以及对
Pause-training takes a step beyond the paradigm of “immediate” next-token prediction in language models. The key idea is to train models with (dummy)
tokens tokens so that the model can learn to harness the additional inference-time computation. We demonstrate that this can improve performance on a variety of our tasks, if we train with tokens both during pretraining and downstream finetuning.
四、总结
同样都是讲故事,而且方法和模型也很类似,但是写的不如Vision Transformers Need Registers这篇文章精彩,另外它总给笔者一种在“把完全不怎么work的东西写成一篇看起来很不错的文章”的感觉。
五、推荐相关阅读
Vision Transformers Need Registers